
From: Poland
Location: Katowice, PL
On Useme since 15 June 2020

SUCCESSFUL: 6
DISPUTED: 0
FAILED: 0
I am a Python developer with many years of experience. I offer scraper bots to scrape data from static and dynamic websites. In some cases also after logging. In addition, I deal with a text file operations, from cleaning files with duplicate / redundant data, to converting file extensions, other amongst I support these file extensions: .json, .csv, .xlsx, .txt, .log, and much more, for your special requests please contact.
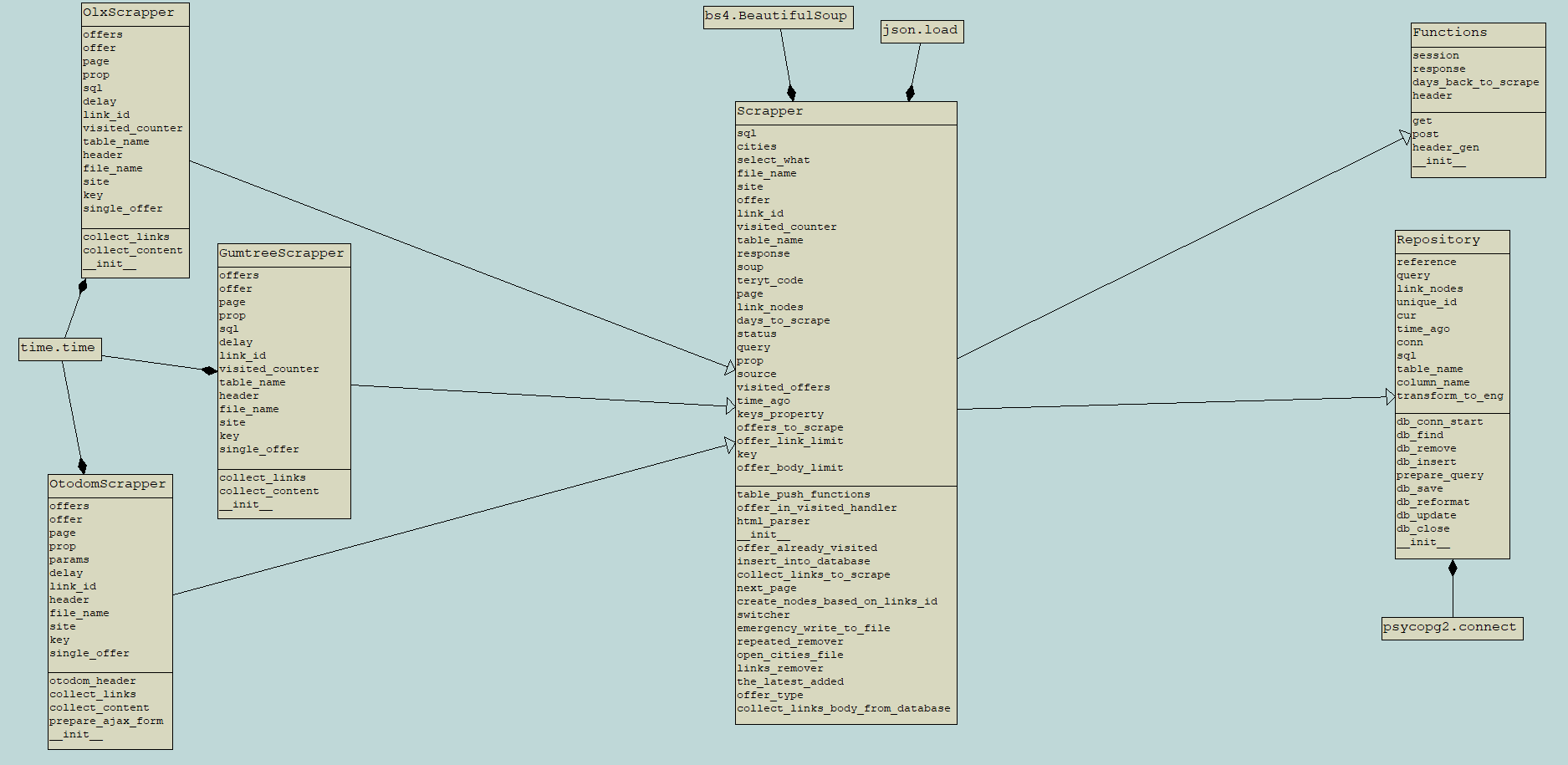
As the first stage of work, the application searches through advertisements that have appeared since the previous scrape. Ads are searched using the default location data serviced by websites. Then, after obtaining all the newly available offers,...
As the first stage of work, the application searches through advertisements that have appeared since the previous scrape. Ads are searched using the default location data serviced by websites. Then, after obtaining all the newly available offers,...
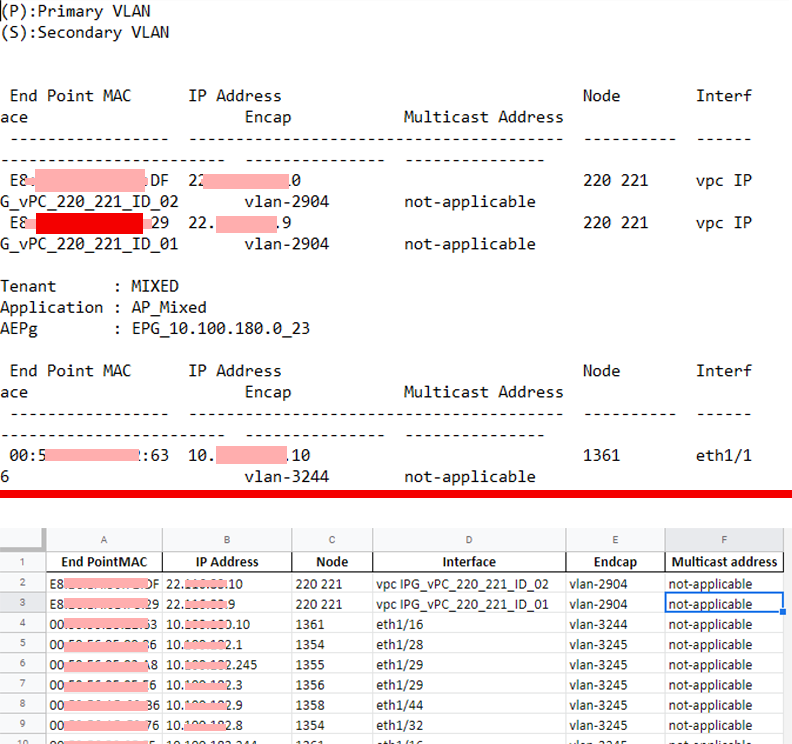
The assumption of the project was to extract data from a text file and standardize them to the Excel.
The assumption of the project was to extract data from a text file and standardize them to the Excel.
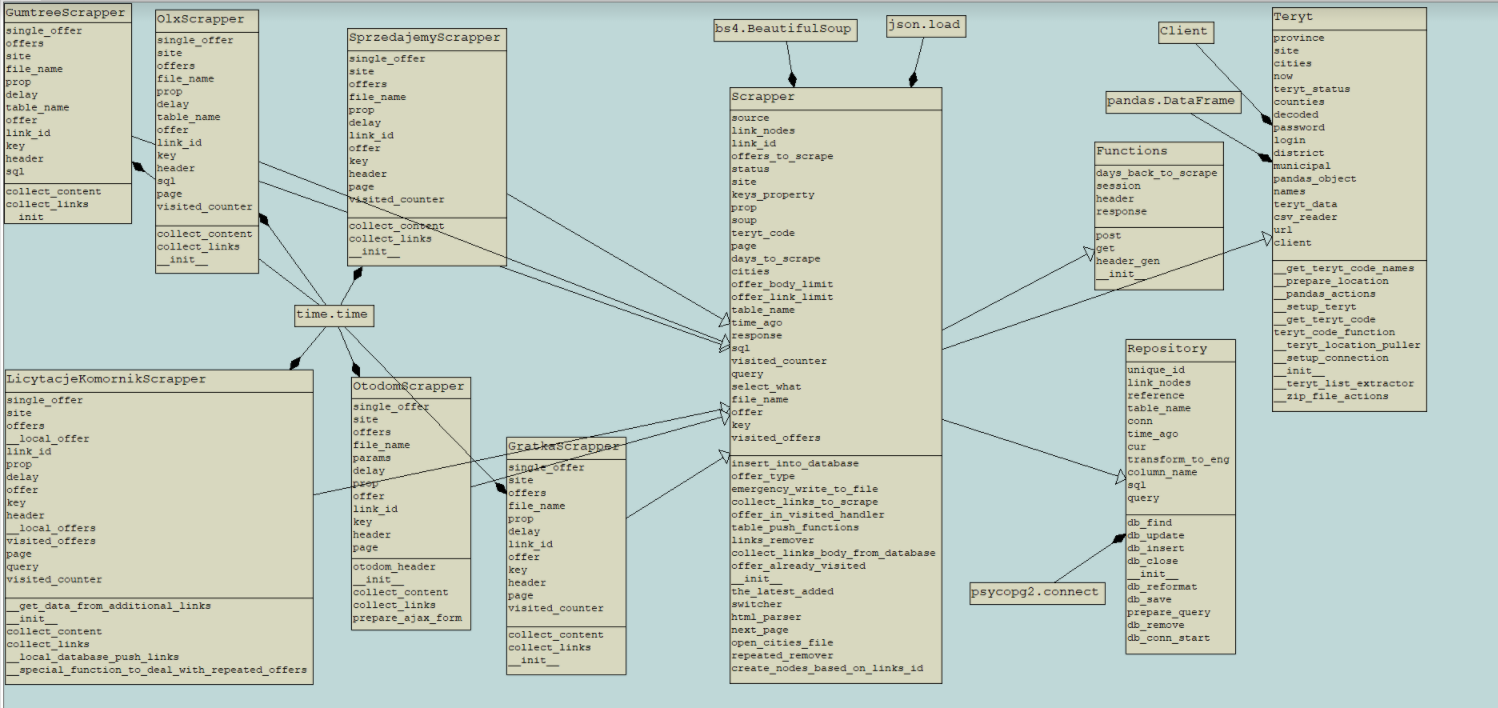
Building a scraper bot to download data from websites: gratka.pl, sprzedajemy.pl, licytacje.komornik.pl. Everything connected to the PostgreSQL database and data optimization mechanisms.
Building a scraper bot to download data from websites: gratka.pl, sprzedajemy.pl, licytacje.komornik.pl. Everything connected to the PostgreSQL database and data optimization mechanisms.
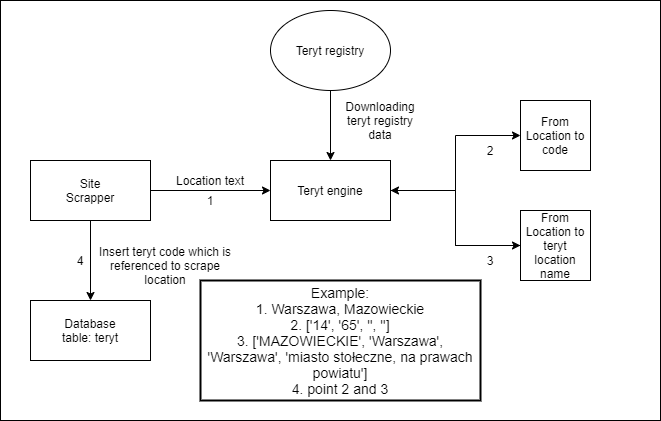
Integration of the scraper with the teryt register, which enables the normalization of the location to unified data.
Integration of the scraper with the teryt register, which enables the normalization of the location to unified data.