
Kraj: Poland
Lokalizacja: Katowice, PL
Na Useme od 15 czerwca 2020

ZAKOŃCZONYCH: 6
SPORNYCH: 0
ZERWANYCH: 0
Jestem programistą Python z wieloletnim doświadczeniem. Oferuje budowę botów do pobierania danych ze stron internetowych, statycznych jak i dynamicznych. W szczególnych przypadkach nawet za bariera logowania. Ponadto zajmuje się operacjami na plikach tekstowych, od oczyszczania plików z duplikatów / zbędnych danych po konwersję rozszerzeń plików, między innymi wspieram te rozszerzenia plików: .json, .csv, .xlsx, .txt, .log, oraz wiele więcej, o specjalne zapotrzebowania proszę o kontakt.
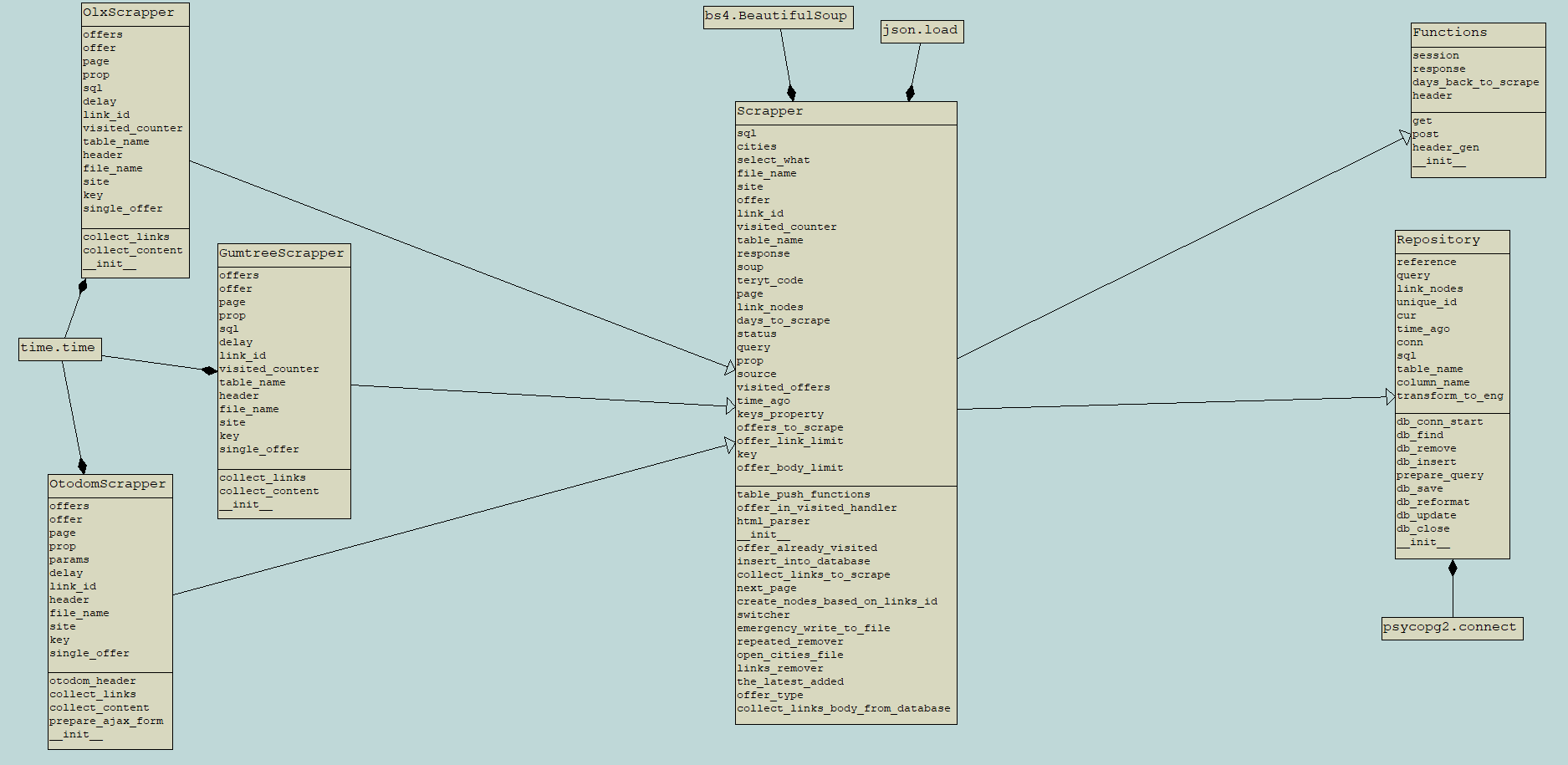
Zasada działania - jako pierwszy etap prac, aplikacja przeszukuje ogłoszenia, które pojawiły się od czasu poprzedniego scrapu. Ogłoszenia są wyszukiwane za pomocą domyślnych danych lokalizacyjnych obsługiwanych poprzez strony. Następnie po...
Zasada działania - jako pierwszy etap prac, aplikacja przeszukuje ogłoszenia, które pojawiły się od czasu poprzedniego scrapu. Ogłoszenia są wyszukiwane za pomocą domyślnych danych lokalizacyjnych obsługiwanych poprzez strony. Następnie po...
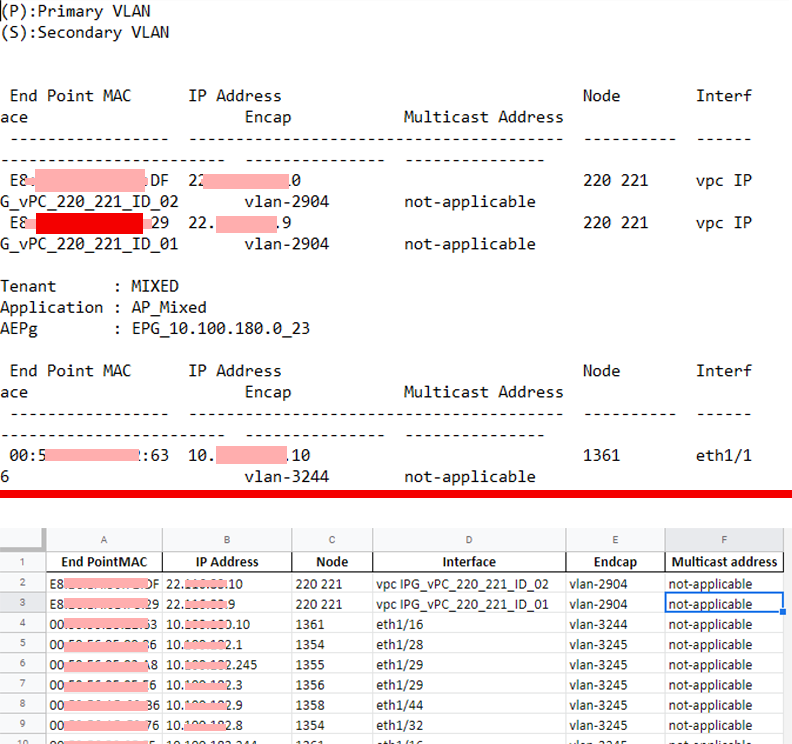
Założeniem projektu było wyodrębnienie danych z pliku tekstowego i znormalizowanie ich do postaci Excel.
Założeniem projektu było wyodrębnienie danych z pliku tekstowego i znormalizowanie ich do postaci Excel.
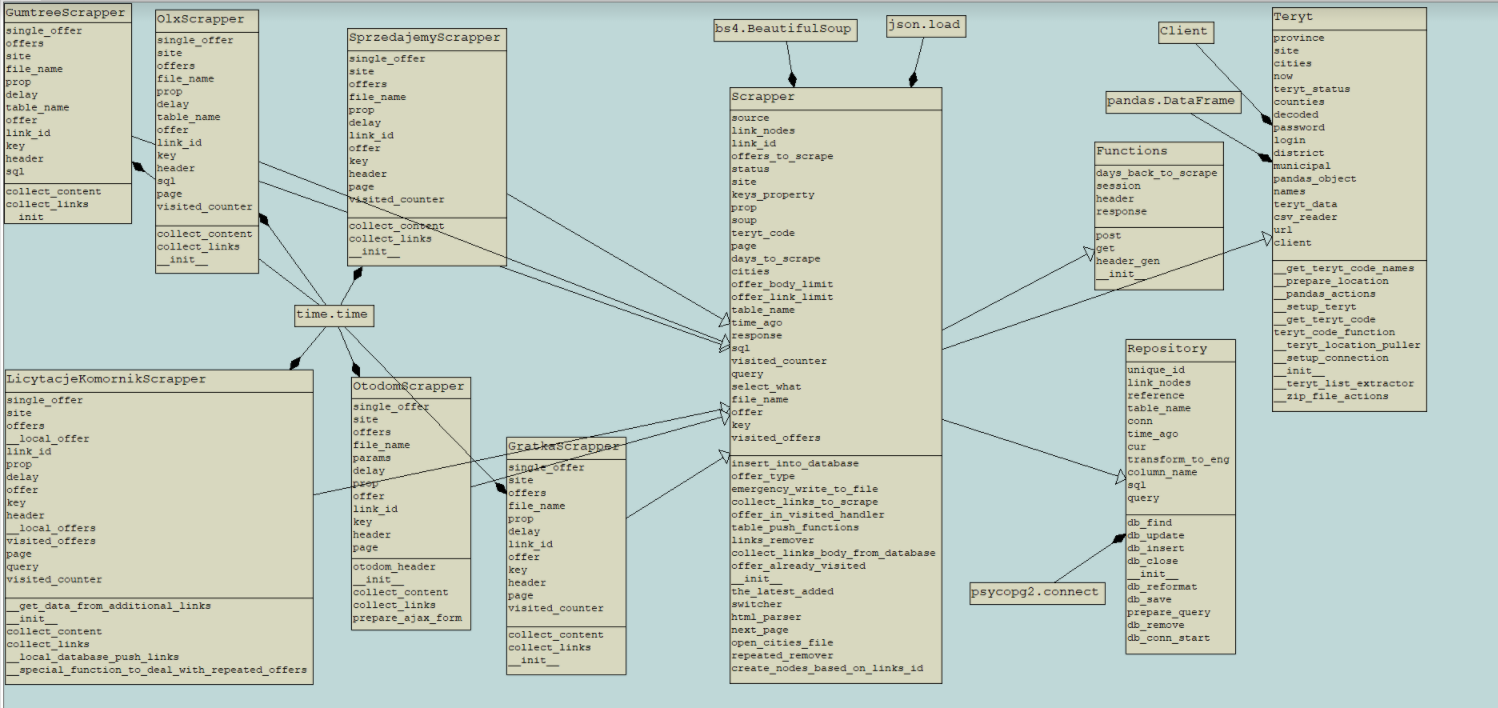
Budowa bota do pobierania danych ze stron gratka.pl, sprzedajemy.pl, licytacje.komornik.pl. Całość połączona z bazą danych PostgreSQL oraz mechanizmami optymalizacji wprowadzanych danych.
Budowa bota do pobierania danych ze stron gratka.pl, sprzedajemy.pl, licytacje.komornik.pl. Całość połączona z bazą danych PostgreSQL oraz mechanizmami optymalizacji wprowadzanych danych.
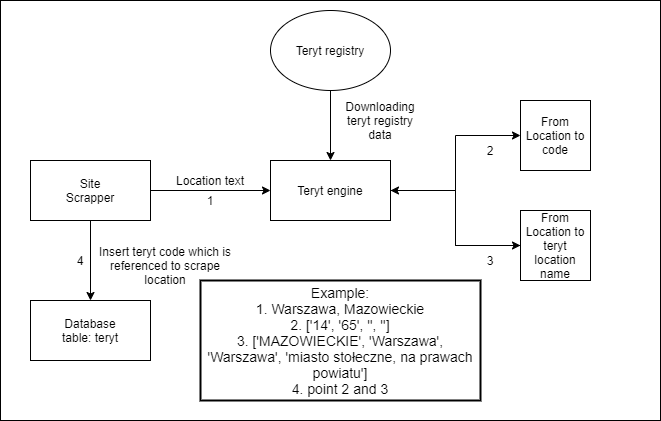
Integracja scrapera z rejestrem teryt, co umożliwia normalizacje lokalizacji do ujednoliconych danych.
Integracja scrapera z rejestrem teryt, co umożliwia normalizacje lokalizacji do ujednoliconych danych.